
SwiftData 教程与示例:定义 Relationship 关系(三)
了解如何使用 SwiftData 中的 @Relationship 宏来定义不同数据模型之间的关联方式,例如删除规则、反向引用等。


@Relationship 宏在 SwiftData 中用于定义实体之间的数据关联关系。
- 删除规则:管理关联对象在删除操作中的处理方式。例如,删除父对象时是否也删除子对象,或者是否只解除关联。
- 反向关系:一个模型可以知道另一个模型对它的引用(或者互相引用),这种反向关系可以帮助模型双向导航,确保数据模型之间的逻辑关联正确实现。
使用 SwiftData 存储小红书数据(示例)
让我们思考如何使用 SwiftData 来存储类似于小红书 App 的数据结构,并通过这个示例来理解 SwiftData 中的 relationship。
小红书中关于笔记和评论的数据模型可能是这样的:
- 每条笔记(Note)可以有多条评论(Comment)。
- 每条评论只能属于一条笔记。
- 删除评论时不影响笔记。
- 删除笔记时,相关评论也会被一并删除。
根据上述需求,可以定义一个一对多的关系来管理 "笔记" 和 "评论" 的数据模型。
创建一对多关系数据模型
首先,可以像下面这样定义基本的数据结构:
@Model
class Note {
@Attribute(.primaryKey) var id: UUID
var title: String
var content: String
var comments: [Comment]()
init(title: String, content: String) {
self.id = UUID()
self.title = title
self.content = content
self.comments = []
}
}@Model
class Comment {
@Attribute(.primaryKey) var id: UUID
var text: String
var note: Note?
init(text: String, note: Note) {
self.id = UUID()
self.text = text
self.note = note
}
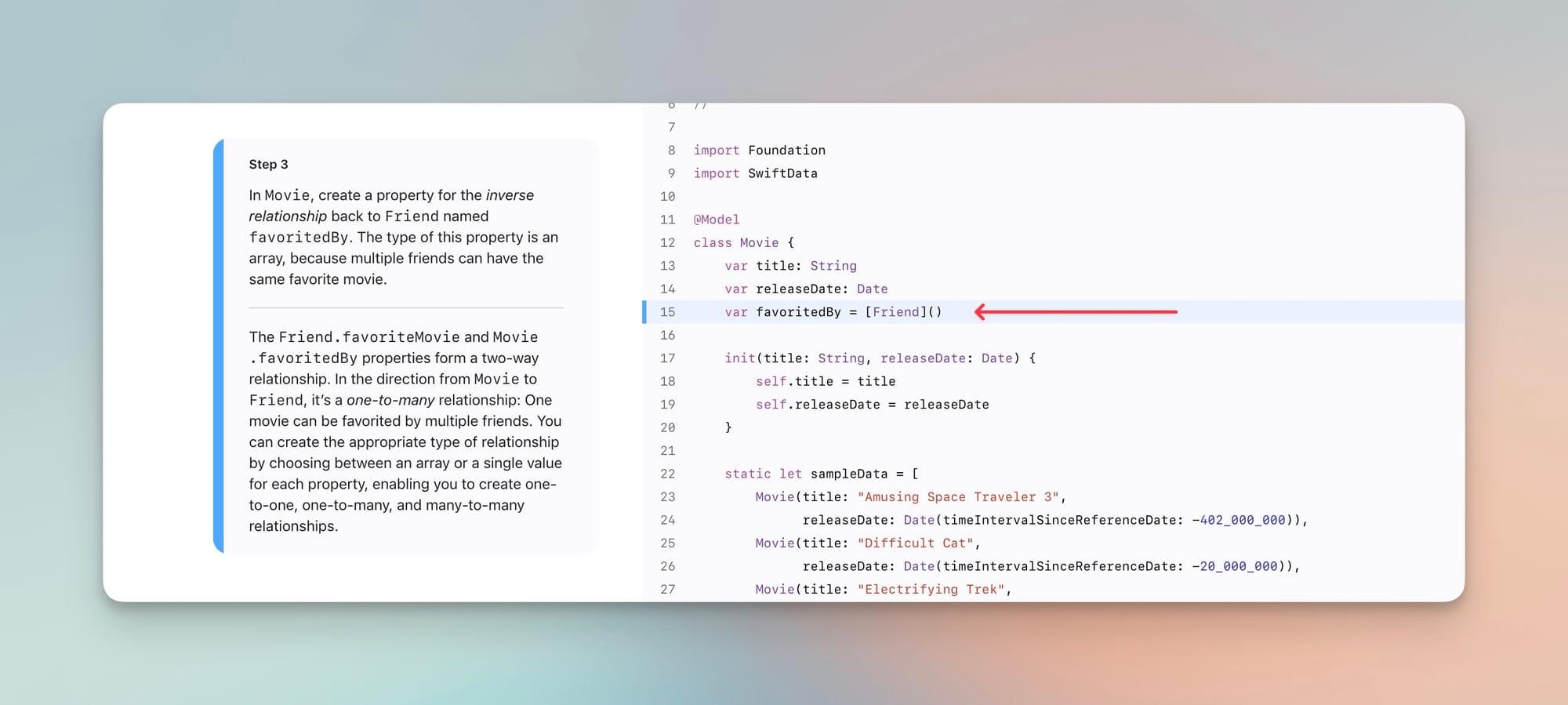
}通过在 Note 中使用数组comments:[Comment]() 属性,表示一个笔记可以有多条评论。
注意,最佳实践通常推荐这样写:
var comments: [Comment]()
//这是一种初始化语法,表示 comments 变量是一个空的 Comment 数组,并且在定义时立即初始化为空数组。
//等效于:var comments: [Comment] = []而不是:
var comments: [Comment]
//这是一种类型声明,表示 comments 是一个可变的 Comment 数组类型,但它尚未初始化。第一种语法,确保comments 在创建时已经是一个有效的空数组,这样可以避免未初始化的错误。在 Apple developer 官方教程中,也是这样的写法:

为什么需要使用 @Relationship?
@Relationship 实际上解决的是数据关联的问题。
刚才我们已经定义了 Note 和 Comment 数据模型,这种设计在表面上看似可行,但在实际应用中存在诸多问题。
例如,现在数据库中有 3 条笔记,15 条评论,每个笔记关联 5 条评论,如何知道是哪 5 条评论对应哪 1 条笔记呢?
第一种做法是:每次创建一个 Comment 实例时,都同时保存一个完整的Note 实例。
假设一条笔记有 1000 条评论,那么就会存储 1000 次笔记内容。如果笔记是视频,文件大小将变得不可承受,这会导致数据冗余,因为同一个Note 可能会被多次存储。进而还会引发数据一致性的问题,例如 Note 被修改更新如何处理?——因此这种方式是不可行的。
第二种方法是:参考现实世界如何管理人的方式,为每个 Comment 实例和 Note 实例都分配一个身份证(ID),相同的 Comment 和 Note 只存储一次。
这样就解决了数据冗余与一次性的问题,这种方法也是现在普遍采用的方法。缺点是需要手动维护Note 和 Comment 之间的关联关系表,每次新增、删除数据时都需要手动更新引用关系,这在技术上不难实现,但是很麻烦。
@Relationship 属性包装器的引入正是为了解决上述问题。它采用第二种方式管理数据之间的关系,但是完全自动化完成,只需要明确清楚数据模型之间的相关关系,SwiftData 底层就会自动维护关联关系,并且比自定义实现更加可靠、高效。
明确定义反向关系(Inverse)
在上述例子中,Note 与 Comment 模型存在引用关系(在 Note 中引用了 Comment 模型,在 Comment 中也引用了 Note),此时就需要使用 Inverse 参数明确定义双向关系。
通过 inverse 参数,SwiftData 可以确保在操作一方的关系时,另一方能够自动更新并同步关系状态。
使用 inverse 参数,需要遵循两个基本要求:
- 只需在其中一个模型类型中标记
inverse关系。如果两边都定义 inverse 参数,则会出现相互引用的错误。 - 通常,
inverse属性应该标记在 "从属" 的一方,即从关系上来看,它是依赖于另一个对象的。例如,应该在 Comment(评论) 模型中标记inverse,因为评论是依赖于 Note(笔记) 的。
评论属于笔记,而不是相反。因此评论模型应该知道它属于哪个笔记。在 Comment 中标记 inverse,当你操作笔记时,SwiftData 会自动知道它关联的评论列表:
@Model
class Comment {
@Attribute(.primaryKey) var id: UUID
var text: String
@Relationship(inverse: \Note.comments)
var note: Note?
init(text: String, note: Note) {
self.id = UUID()
self.text = text
self.note = note
}
}明确定义删除规则(DeleteRule)
DeleteRule 决定了当源对象被删除时,关联的目标对象将如何处理。
@Relationship(deleteRule: .cascade, inverse: \Book.author)
var books: [Book]
- 使用
.cascade删除Author时,所有关联的Book也会被删除。
@Relationship(deleteRule: .nullify, inverse: \Author.books) var author: Author?
- 使用
.nullify删除Author时,Book的author属性会被置为nil。
SwiftData 提供了几种删除规则:
.cascade:删除源对象时,关联的目标对象也会被删除。.nullify:删除源对象时,关联的目标对象的关系会被置为 nil。.deny:如果存在关联的目标对象,阻止删除源对象。.noAction:删除源对象时,不对关联的目标对象采取任何操作。
在 Note 模型中,通过指定deleteRule 为 .cascade,实现当删除笔记时,同时删除所有的关联评论:
@Model
class Note {
@Attribute(.primaryKey) var id: UUID
var title: String
var content: String
@Relationship(deleteRule: .cascade)
var comments: [Comment]()
init(title: String, content: String) {
self.id = UUID()
self.title = title
self.content = content
self.comments = []
}
}在 Comment 模型中,deleteRule 为 .nullify,这表示当笔记删除时,不会影响评论的存储,只是将 note 的关系置为空:
@Model
class Comment {
@Attribute(.primaryKey) var id: UUID
var text: String
@Relationship(deleteRule: .nullify, inverse: \Note.comments)
var note: Note?
init(text: String, note: Note) {
self.id = UUID()
self.text = text
self.note = note
}
}更多 SwiftData 相关教程
 廖林
廖林 廖林廖林
廖林廖林