
SwiftData 教程与实例:简化 iOS 开发数据持久化(一)
SwiftData 是 Apple 为 iOS 开发者提供的新型类 ORM 工具,简化数据库管理,无需编写 SQL,本文包含 SwiftData 教程和使用实例。


SwiftData 是 Apple 在 Swift 语言生态中推出的一项新的数据管理框架,旨在简化开发者处理数据持久化的工作。它在 WWDC 2023 上首次亮相,作为 Core Data 的进化和替代方案。SwiftData 提供了更符合 Swift 语言风格的 API 和语法,使数据模型的定义和操作更加直观和简洁。
如果你刚接触软件开发,我将从零开始向你解释 SwiftData 是什么,以及它在开发中的作用。通过这篇文章的讲解,我相信你会轻松理解。
理解 SwiftData 的作用与功能
使用数据库面临的问题
在软件开发中,我们需要处理和存储各种类型的数据。
通常可以将数据分为以下几类:
- 大文件类型:例如视频、音乐或图片。这类数据通常非常庞大,并且不需要复杂的结构化存储。它们可以直接存储在硬盘上,或者通过云存储等方式管理。
- 非结构化的文本类型:如文章、博客或文档。通常使用简单的文件格式(如 .txt 文件)来存储这些数据,不需要复杂的处理。
- 结构化的文本数据:这是最常见的一种数据类型,例如你注册微博账号时,输入的姓名、性别、生日等信息。它们彼此关联,形成一条完整的记录,称为“数据条目”。这种数据需要存放在一起,因此使用数据库来进行存储和管理是最佳的选择。
在使用数据库存储数据时,通常的步骤包括:
- 创建并连接数据库:首先需要设置数据库,并确保应用可以与之通信。
- 创建表并定义数据结构:接着,创建表格并定义数据结构,例如表中的字段(如“姓名”、“生日”等)。
- 进行增删改查操作:开发者可以对表中的数据进行插入(增)、删除、更新或查询操作。
为了执行这些操作,传统上我们使用一种叫做 SQL(结构化查询语言)的工具。例如,向数据库插入一条微博用户信息的 SQL 语句可能看起来像这样:
INSERT INTO users (name, gender, birthday) VALUES ('张三', 'male', '1990-01-01');
然而,随着软件开发的发展,使用数据库逐渐遇到了两个主要问题:
问题一:不同数据库 SQL 语句存在差异
为了应对不同的使用场景(如并发量、扩展性、数据一致性等),诞生了许多不同的数据库系统,如 MySQL、SQL Server 和 PostgreSQL 等。尽管它们都支持 SQL,但在某些 SQL 语法和特性上存在差异。
因此,当业务需求使得我们需要从一种数据库迁移到另一种时(如从 MySQL 迁移到 PostgreSQL),可能需要修改大量 SQL 语句,这使得迁移工作繁琐。
问题二:不同编程语言与 SQL 的不兼容
随着软件开发的发展,越来越多的编程语言和工具被发明出来,不同的场景中,开发者会使用不同的语言。开发者在开发 iOS 应用时可能会使用 Objective-C 或 Swift,数据分析通常使用 Python,而 Java 则常用于大型企业系统。然而,精通这些编程语言的开发者未必擅长 SQL 语言。
使用 ORM 工具操作数据库
为了解决上述问题,ORM(对象关系映射)工具应运而生。ORM 是编程语言到 SQL 语句的映射工具,开发者只需用自己熟悉的编程语言来操作数据库,ORM 工具会将这些操作自动转换为 SQL 语句并处理底层数据库的交互。比如在 Python 中,常用的 ORM 工具是 SQLAlchemy。
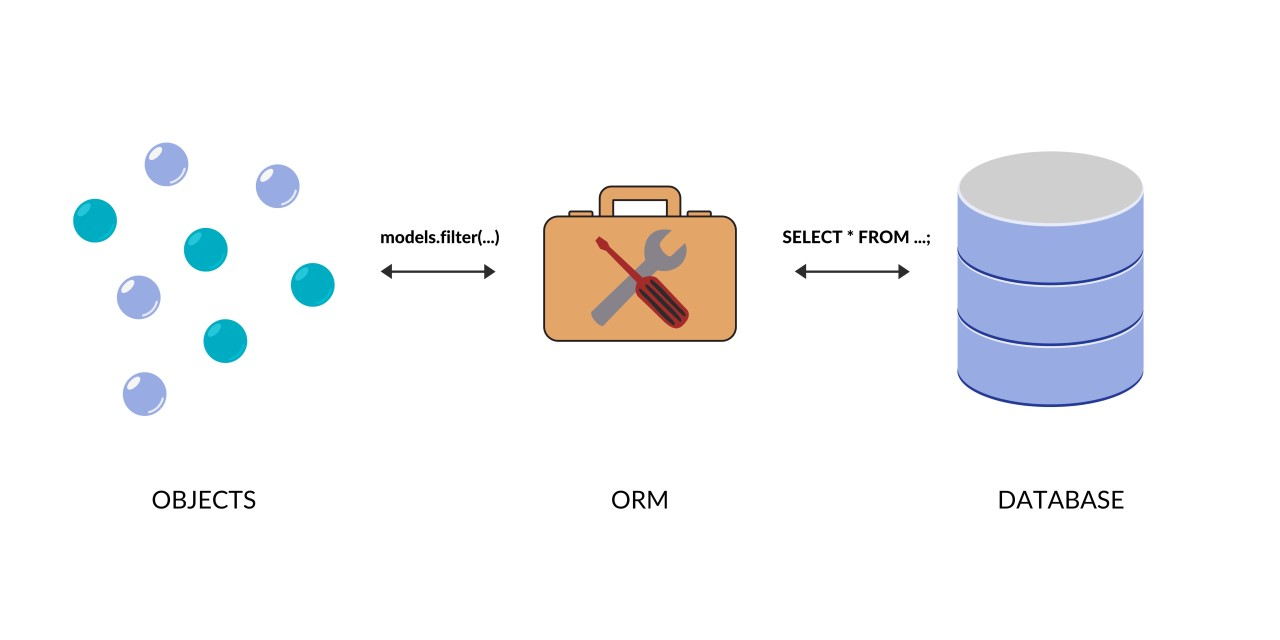
如果不使用 ORM(SQLAlchemy) 工具,我们可能需要直接编写 SQL 代码来操作数据库,如下所示:
import sqlite3
# 连接数据库
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
# 创建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT,
gender TEXT,
birthday TEXT
)
''')
# 插入数据
cursor.execute('''
INSERT INTO users (name, gender, birthday) VALUES (?, ?, ?)
''', ('张三', 'male', '1990-01-01'))
# 提交并关闭连接
conn.commit()
conn.close()使用 SQLAlchemy 后,操作可以简化为 Python 原生语法:
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# 定义基础类
Base = declarative_base()
# 定义用户表结构
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
gender = Column(String)
birthday = Column(String)
# 创建数据库引擎
engine = create_engine('sqlite:///example.db')
# 创建表
Base.metadata.create_all(engine)
# 创建会话
Session = sessionmaker(bind=engine)
session = Session()
# 插入数据
new_user = User(name='张三', gender='male', birthday='1990-01-01')
session.add(new_user)
# 提交事务
session.commit()
# 关闭会话
session.close()并且由于 ORM 的数据库无关性,开发者能够在不修改业务逻辑代码的前提下切换数据库系统,而无需手动调整 SQL 语句。
SwiftData 与 QRM
SwiftData 和 ORM 工具在数据管理的核心思想上非常相似。就像传统的 ORM 工具,SwiftData 允许开发者只使用 Swift 语言中的类和对象来定义和管理数据库中的数据结构,而无需编写 SQL 语句。
但与传统的 ORM 相比,SwiftData 进一步简化了底层数据库的操作。使用 ORM 我们仍然需要手动创建与连接数据库,但 SwiftData 会自动处理所有数据库的创建和连接,开发者无需过多关心底层实现。
理解 SwiftData 工作原理
理解 SwiftData 的作用之后,在深入具体的代码细节之前,我们从高层次来探讨它的工作原理。不过首先,我们可以先回顾一下传统 ORM 工具的工作方式,以便更好地理解 SwiftData 的工作方式。
传统 ORM 的工作原理
以 Python 中流行的 ORM 工具 SQLAlchemy 为例,其架构可以分为以下几个部分:
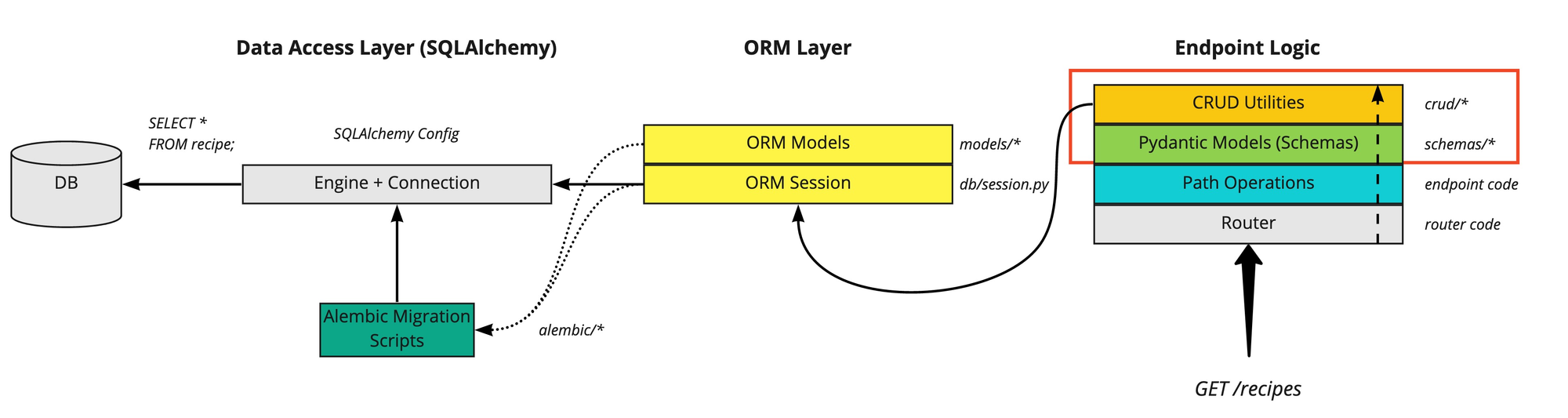
首先,我们需要创建一个 Engine,它工作在数据访问层,我们可以把它简单理解为一个“数据库连接信息管理器”,它会负责与底层数据库进行交互,并处理数据库连接的相关信息。
然后,在 ORM 层,我们需要创建 Models 和 Session。
- Models 是用来定义数据模型的结构,它们直接映射到数据库中的表。
- Session 是用来与数据库建立会话的工具。这里需要注意,Session 和 Engine 是不同的:Engine 管理底层的数据库连接方式,而 Session 则从 Engine 中获取连接并创建一个具体的会话,用于执行数据库操作。
最后,在应用程序的终端逻辑层,通过 Session 进行 CRUD 操作(创建、读取、更新、删除)。这些操作通过 ORM 的机制,将应用中的请求转换成适合目标数据库的 SQL 语句。
在这个架构中,应用程序发起的 CRUD 请求会通过 Engine 生成相应的 SQL 语句(SQLAlchemy 能自动识别并适配不同类型的数据库)。这些 SQL 语句的生成是基于 Models 定义的数据结构,而具体的数据库操作则通过 Session 会话完成。
SwiftData 的工作原理
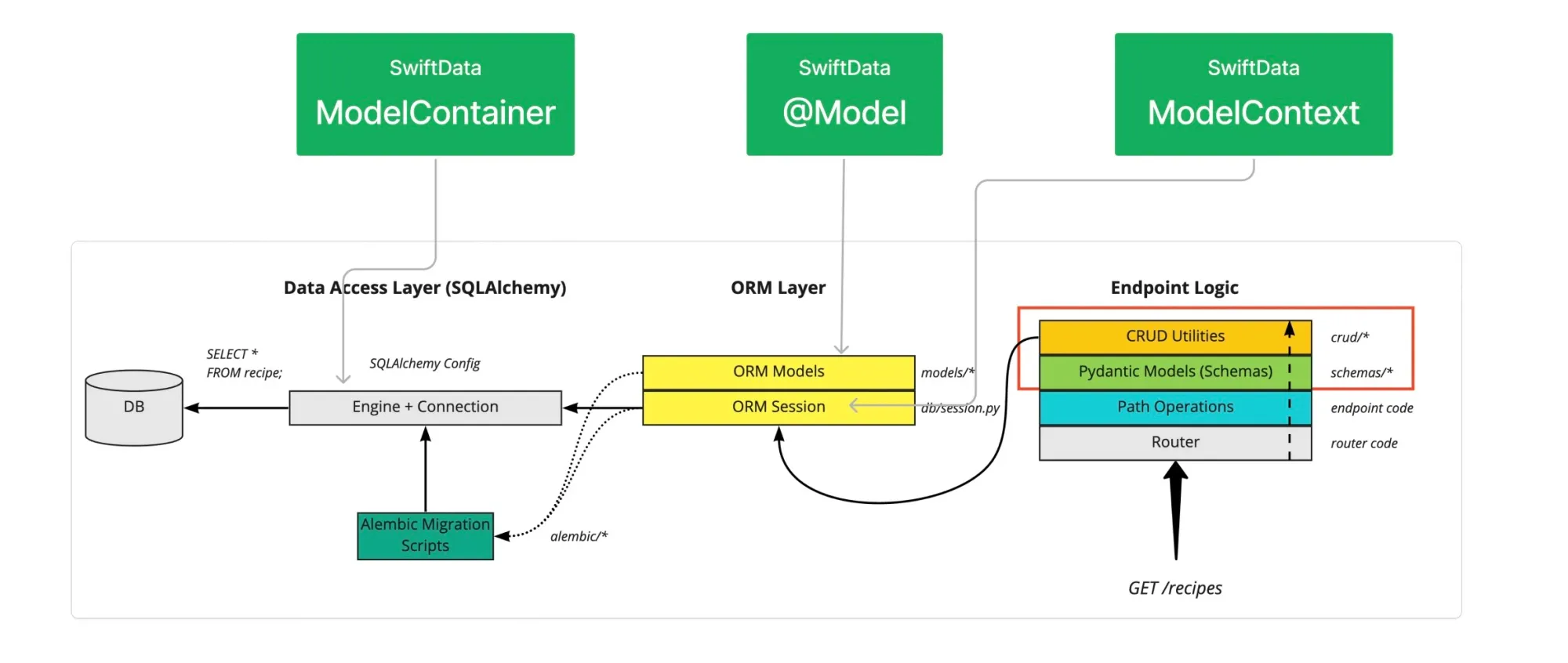
ModelContainer
在 SQLAlchemy 中,Engine 是数据库的连接管理器,负责与底层数据库建立连接并进行数据交互。每次应用程序需要访问数据库时,Engine 都会根据数据库类型生成相应的 SQL 语句,并建立连接。
SwiftData 使用模型容器(ModelContainer) 来管理与数据库的连接和数据交互。它类似于 SQLAlchemy 中的 Engine,但比 Engine 更加简单。
- 在 SQLAlchemy 中,开发者需要手动创建 Engine 并配置数据库连接信息(例如连接地址,账户密码等)
- 在 SwiftData 中,SwiftData 会自动处理这些底层的数据库相关操作,所有这些底层数据库对开发者来说是不可见的,你可以直接使用 ModelContainer。
@Model
在 SQLAlchemy 中,Models 是数据模型的定义,直接映射到数据库中的表。开发者需要手动定义这些模型,以描述数据库中的表结构和字段。
SwiftData 中使用@Model 标记需要持久化的 Swift 类,自动生成与这些类相对应的数据库表。两者都通过编写类定义来生成数据库表结构。
ModelContext
在 SQLAlchemy 中,Session 负责管理与数据库的具体会话。它是从 Engine 中获取数据库连接,并通过它来执行数据库的增删改查(CRUD)操作。每个 Session 实际上代表一次与数据库的交互。
SwiftData 中,上下文环境(ModelContext) 类似于 ORM 工具中的 Session。它负责管理与数据库的交互,并在上下文中执行 CRUD 操作。SwiftData 的 ModelContext 自动处理事务管理,开发者可以通过 ModelContext 插入、更新、删除或查询数据。
更多开发教程
 廖林
廖林 廖林
廖林 廖林
廖林